
What is Phonetics?
Phonetics is the study of the articulatory and acoustic properties of the sounds of human language.
Lessons:

The Physics and Physiology of Speech
Vowels
Consonants: Voicing and Place of Articulation
Acoustics
Consonants: Manner of Articulation
Formants
Extracting Formant Values
The Physics and Physiology of Speech
Introduction
In this lesson, you will be introduced to the major anatomical components of the speech system for human language.
Major Terms
-
trachea
-
larynx
-
glottis
-
pharynx
-
vocal tract
Subglottal System
Sound in human language is produced by the regulation of airflow from the lungs through the throat, nose, and mouth. This airflow is altered in various ways by different aspects of this speech system. The first major segment of the speech system is the subglottal system. This subglottal system comprises the lungs, diaphragm and trachea.
The lungs are basically a pair of balloon-like sacs that inflate or deflate by the action of the diaphragm, a muscle just under the lungs, attached to them. When the diaphragm is lowered, the lungs inflate, and when the diaphragm is raised, air is pressed out of the lungs, allowing them to deflate.
When this air is pressed out of the lungs, air travels up the trachea, or windpipe, to the larynx, the next major segment of the speech system.
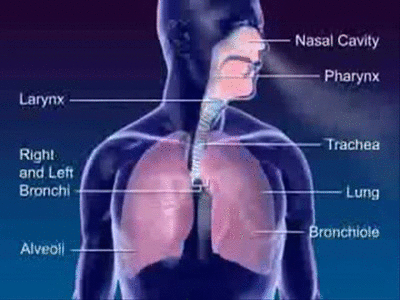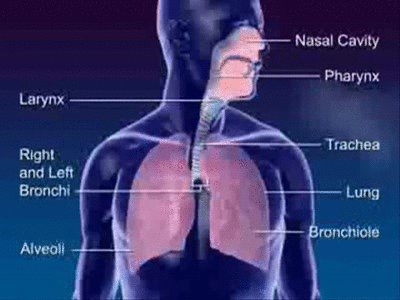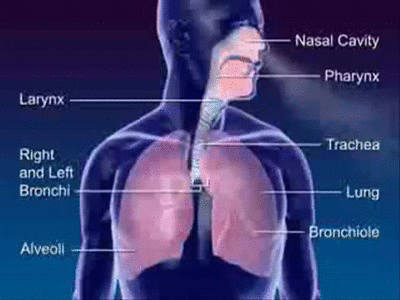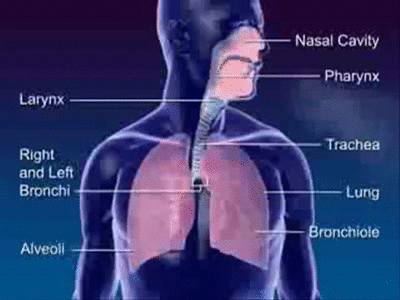
The Larynx
The larynx is a mass of cartilage at the top of the trachea. It is commonly called the voicebox.
The larynx contains folds of muscle called the vocal folds (sometimes called vocal cords). These vocal folds are connected to the larynx by the arytenoid cartilage at the front, but the other ends are left free. The opening between the vocal folds is known as the glottis. These folds can be relaxed, letting air flow freely through the glottis, or tensed, so that the air vibrates as it passes through the glottis.
Sounds that are produced with relaxed vocal folds are known as voiceless sounds, and sounds that are produced with tensed vocal folds are known as voiced sounds. If the folds are only partially closed, a whispered sound is produced.

Above the Larynx
The area above the larynx consists of three main areas: the pharynx, the nasal cavity, and the oral cavity. The pharynx consists of the area above the larynx and below the uvula. The oral cavity is the area from the back of the throat to the mouth. The major parts of the oral cavity that are used in speech production are the uvula, the velum, the tongue, the hard palate, the alveolar ridge, the teeth, and the lips. The uvula is that fleshy blob that hangs down in the back of the throat. The velum is the soft palate, and the alveolar ridge is a mass of hard cartilage behind the teeth.
The following graphic shows these major parts of the area, which is also known as the supraglottal system
Summary
In summary, this lesson has outlined the major parts of the anatomy that relate to speech production. These parts are the following:
-
Subglottal system, including lungs and trachea
-
Larynx, including the vocal folds and glottis
-
Supraglottal system, including the oral cavity, nasal cavity, and pharynx
In the next lesson, you will learn how consonants are classified in terms of the use of these parts of the speech system.



Consonants:
Voicing and Place of Articulation
Introduction
In this lesson, the goals are to begin to learn how speech sounds are classified in terms of their use of the speech system.
Major Terms
-
voicing
-
place of articulation
-
bilabial
-
labiodental
-
interdental
-
dental
-
alveolar
-
alveopalatal
-
palatal
-
velar
-
uvular
-
pharyngeal
-
glottal
-
Voicing
In the last lesson, you were introduced to the following states of the glottis: voiceless and voiced. These states are determined by the action of the vocal folds in the larynx. If the vocal folds are held apart, the glottis is in a voiceless state, while if the vocal folds are held together, and allowed to vibrate, the glottis is in a voiced state.
Certain consonants in human language are distinguished by which state is active during production of the sound. For example, pronounce the sound [m], as in mat, and hold the sound. While producing this sound, place your fingers at the base of your throat. You should feel the vibration of the vocal folds. Since the sound [m] is vibrating, this is a voiced sound.
Now make the sound [p], as in pat. You can't really hold this sound, but again put your fingers near the base of your throat while you say [p]. You shouldn't feel much vibration, if any. This is because the vocal folds are held apart, making a voiceless sound.
Now say the sounds [p] and [b], as in bat, with your fingers at the base of the throat. When you say [p], there should be no vibration, but when you say [b], there should be vibration. Think about what you are doing with your mouth to make both sounds. Both sounds are made in basically the same way, but one is voiceless and one is voiced.
Speech and the Vocal Tract
As described in the earlier lesson, speech sound is created by airflow through the vocal tract. In pulmonic sounds, which are the sounds we will consider here, the lungs push air up into the trachea, through the larynx, and outward through the vocal tract.
So how are different sounds made? In part 1, we discussed that one way to make different sounds is to vary the state of the glottis, making either a voiced or voiceless sound.
Another way is to vary the shape of the vocal tract. Imagine the vocal tract as a tube, through which air passes. If this tube is simply open, the airflow creates a sound. But if you alter the shape of that tube, the airflow moves differently, making a different sound.
Here's an experiment that some of you may have tried. Take an empty bottle and blow air across the top of the bottle. If you can get the airflow just right, you should be able to produce a low sound. Now fill the bottle halfway with water. Blow across the bottle opening again. This time the sound is higher. If you put some more water in the bottle, the sound will get even higher.
What's happening? For a more detailed discussion, you can view the lesson Acoustic Phonetics. However, for now, just understand that if the bottle (vocal tract) is not as filled with water (larger), the sound will be a deep, low sound. If the bottle (vocal tract) is filled with water (smaller), the sound will be a higher sound.
When we make speech sounds, one thing that is happening is that we are varying the shape of the vocal tract, making the sound different. For example, say the sound [t]. To make this sound, you are raising the tip of your tongue behind your teeth and then lowering your tongue. When you do this, the air builds up behind the closure made by your tongue and teeth and is then released. When the air is released by the tongue, the air travels outward through a small area, just from the teeth to outside the mouth.
Now say the sound [k]. To make this sound, you are bringing your tongue up to the velum, closing off the airflow, and then lowering your tongue to release the air. This time, when the air is released, it travels through a larger area before leaving the mouth. This space is from the velum to the lips. Thus, the sound made by the airflow is different from that made by [p].
The following diagrams illustrate the amount of space in the vocal tract available for [t] and [k]:
As the diagram show, there is more space in the vocal tract for the release of air in the production of [k] than for [t]. Therefore, two distinct sounds are produced.
The point at which the vocal tract is altered is known as the place of articulation. In the next section, we will discuss the major places of articulation in classifying human speech sounds.


Place of Articulation
The term place of articulation, as discussed in the last section, classifies speech sounds in terms of where in the vocal tract the shape of the vocal tract is altered. In this section, we will present the major places of articulation.
Bilabial
Bilabial sounds are those sounds made by the articulation of the lips against each other. Examples of such sounds in English are the following: [b], [p], [m].
Labiodental
Labiodental sounds are those sounds made by the articulation of the upper teeth towards the lower lip. Examples of such sounds in English are the following: [f], [v].
Interdental
Interdental sounds are those sounds made by the articulation of the tongue between the teeth. Examples of such sounds in English are the following: [θ], [ð].
Dental
Dental sounds are those sounds made by the articulation of the tip of the tongue towards the back of the teeth. Such sounds are not present in Standard American English, but in some Chicano English dialects and certain Brooklyn dialects, the sounds [t] and [d] are pronounced with a dental articulation.
Alveolar
Alveolar sounds are those sounds made by the articulation of the tip of the tongue towards the alveolar ridge, the ridge of cartilage behind the teeth. Examples of such sounds in English are the following: [t], [d], [s], [z], [n], [l], [ɾ].
Alveopalatal
Alveopalatal sounds are those sounds made by the articulation of the front of the tongue towards the area between the alveolar ridge and the hard palate. Examples of such sounds in English are the following: [ʃ], [ʒ], [t̠ʃ], [d̠ʒ].
Palatal
Palatal sounds are those sounds made by the articulation of the body of the tongue towards the hard palate. An example of such a sound in English is [j].
Velar
Velar sounds are those sounds made by the articulation of the body of the tongue towards the velum. Examples of such sounds in English are the following: [k], [g], [ŋ].
Uvular
Uvular sounds are those sounds made by the articulation of the back of the tongue towards the uvula. Uvular sounds do not exist in English, but the French "r" is pronounced by the uvular sounds [χ] and [ʁ].
Pharyngeal
Pharyngeal sounds are those sounds made by the articulation of the tongue root towards the back of the pharynx. Pharyngeal sounds do not exist in Standard American English, but are found in languages such as Arabic and Hebrew.
Glottal
Glottal sounds are those sounds made at the glottis. Examples of glottal sounds in English are the following: [ʔ], [h].
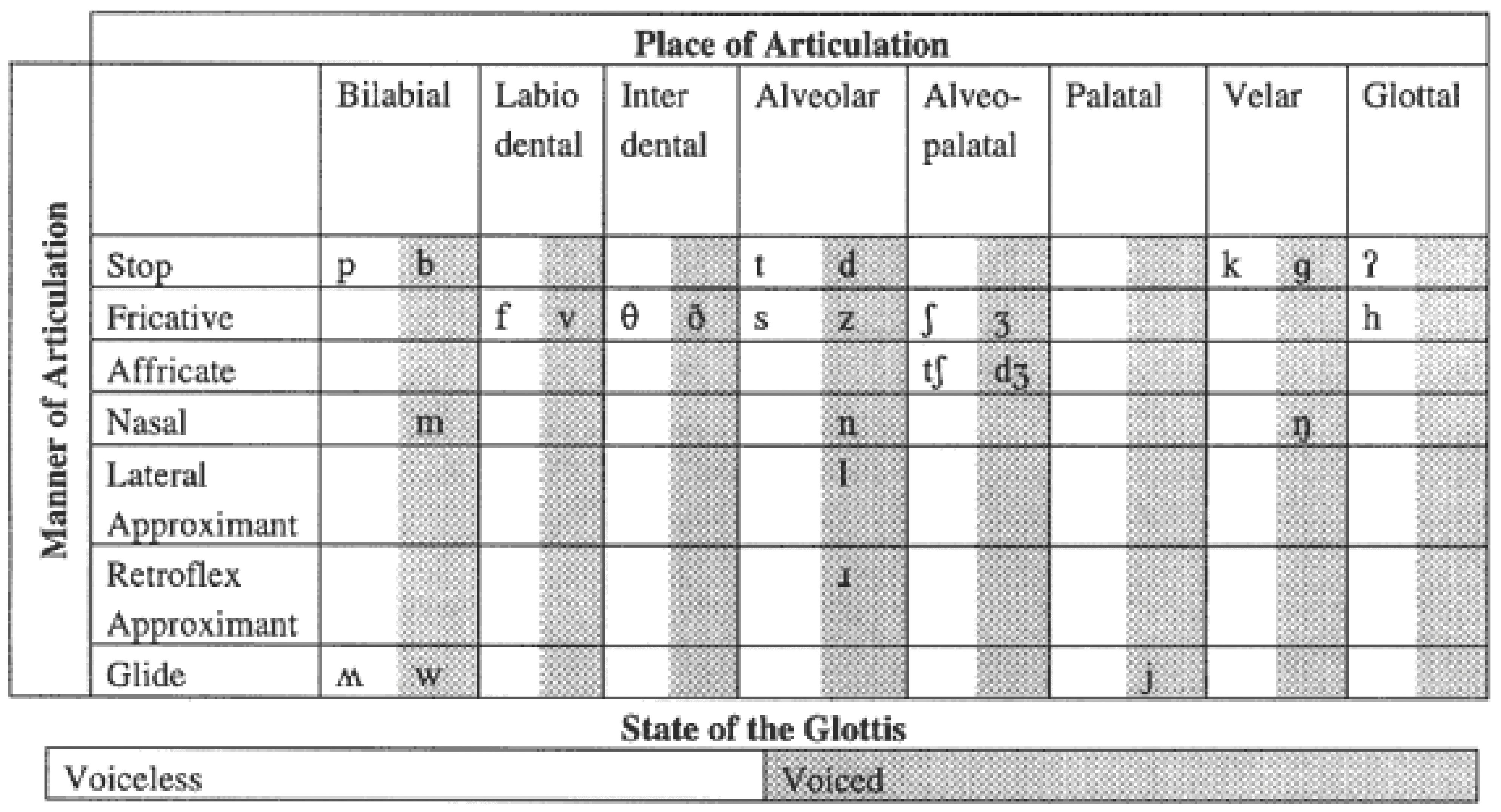
On the next page is a diagram that illustrates all the places of articulation.
Place of Articulation
This diagram illustrates positions of the articulators in the articulation of certain consonants.
In the next lesson, you will learn how consonants are classified on the basis of the manner in which the articulators modulate the airflow.

Consonants:
Manner of Articulation
Introduction
In this lesson, the goals are to continue learning how speech sounds are classified in terms of their use of the speech system.
Major Terms
-
manner of articulation
-
plosive
-
fricative
-
affricate
-
nasal
-
approximant
-
glide
-
Manner of Articulation
In the last lesson, you were introduced to the places of articulation. These are the points in the vocal tract at which the articulators alter the shape of the vocal tract to produce distinct consonant sounds.
However, consonants are further distinguished on the basis of how the articulators alter the shape of the vocal tract. That is, how is the airflow regulated by the tongue or lips.
In the following sections, you will be introduced to the major manners of articulation for pulmonic consonants.
Plosives ( /p/ /b/ /d/ /t/ /k/ /g/)
A plosive is formed by the complete obstruction of the vocal tract by the articulators. This obstruction is then released, allowing the air to "explode" out of the mouth.
When the air is blocked by the articulator, it begins to raise in pressure. Then, when the air is released, the high pressure air rushes out into the lower pressure area beyond the blockage. This results in a burst of air, signifiying a plosive. In the following diagram, the dots represent the pressure of the air. The higher pressure area have more dots per area, while the lower pressure areas have fewer dots per area.
Fricatives (/f/ /v/ /s/ /z/ /∫/ /ʒ/ /θ/ /ð/ /h/)
A fricative is formed by a constriction in the vocal tract by the articulators, such as the tongue or the lips. However, unlike stops, the occlusion (blockage) in the vocal tract is not complete. Some of the air is allowed to come through a very narrow opening. This air becomes turbulent, because of the friction between the airflow and the narrow passage.
Fricatives happen in two ways. One way is simply for the air to flow through a narrow opening, like in the sound [f]. Another ways is for the air to be sped up through a narrow passage and then forced across another area, like the teeth, which is the way the sound is formed. In the following diagram, the dots represent moving air particles. The air behind the occlusion is relatively slow, but the air that is forced between the tongue and the roof of the mouth is much faster and more turbulent.
Affricates (/ʤ/ /ʧ /)
An affricate combines the manners of articulation for the plosive and the fricative. Like a stop, the articulation of the affricate begins with a complete closure of the vocal tract by an articulator. However, when the closure is released, the release is somewhat gradual, providing a narrow space between the articulator and the mouth for the airflow to move through. This narrow space creates an environment similar to a fricative, in that the airflow moving out becomes turbulent for a brief period until full release of the closure.
Nasals (/m/ /n/ /η/)
A nasal is formed by the obstruction of the vocal tract and the lowering of the velum. This lowering of the velum alows the airflow to flow out through the nasal cavity, rather than through the oral cavity.
Approximant (/w/ /j/ /r/ /l/)
An approximant is formed by the constriction of the vocal tract, but with no obstruction in the vocal tract. Therefore, no turbulent airflow, as in a fricative. Instead, the air is allowed to flow freely through the vocal tract.
The sound is also known as a lateral approximant, since the articulators do touch at a central point, but the air is allowed to flow through one or both sides of the contact point.
Other Articulations
There are two other articulations in varieties of English that should be noted here: the tap and the trill.
A tap is formed by a quick contact between an articulator and the vocal tract. In Standard American English, for example, there is the tap , which can be found in the middle of words such as ladder, and butter.
A trill is formed by the rapid vibration of the tongue tip against the roof of the mouth. This vibration is caused by the motion of a current of air. This sound, represented by , is found, for example, in varieties of British and Scots English. It is also known as a "rolled r".
Summary
In this lesson, you have been introduced to several manners of articulation. These are listed below:
-
Plosive
-
Formed by a blockage of the vocal tract, followed by an explosive release of air
-
-
Fricative
-
Formed by slight contact between articulators, allowing turbulent airflow
-
-
Affricate
-
Formed by a blockage of the vocal tract, like plosive, followed by a gradual release of turbulent air, like a fricative
-
-
Nasal
-
Formed by the lowering of the velum, allowing air to flow through the nasal cavity
-
-
Approximant
-
Formed by the constriction of the vocal tract, but with no blockage of the airflow
-
-
Tap
-
Formed by a quick contact between articulators
-
-
Trill
-
Formed by the rapid vibration of the tongue tip by a current of air
-
Vowels
Introduction
In this lesson, the goals are discuss how vowel sounds are classified in terms of their use of the speech system.
Major Terms
-
tongue height
-
tongue backness
-
lip rounding
-
tense
-
lax
Vowel Classification
In the last two lessons, you were introduced to the classification of consonant sounds. The classification of consonants were shown to be based on three aspects of articulation: place of articulation, manner of articulation, and voicing.
In this lesson, you will be introduced to the classification of vowel sounds. The classifcation of vowels is based on four major aspects: tongue height, tongue backness, lip rounding, and the tenseness of the articulators.
Tongue Height
The first aspect of vowel classification that you will be introduced to is that of tongue height. Vowels are classified in terms of how much space there is between the tongue and the roof of the mouth, which is determined by the height of the tongue.
There are three primary height distinctions among vowels: high, low, and mid.
In English, examples of high vowels are [i], [ɪ], [u], [ʊ]. These are vowels with a relatively narrow space between the tongue and the roof of the mouth. Examples of low vowels are [æ], [a] . These are vowels with a relatively wide space between the tongue and the roof of the mouth. Examples of mid vowels are [e], [ɛ], [o], [ɔ] . These are vowels whose tongue positions are roughly between the high and low vowels.
These classifications are quite relative, as different languages have different canonical tongue heights for different classifications.
Tongue Backness
The second aspect of vowel classification that you will be introduced to is that of tongue backness. Vowels are classified in terms of how far the raised body of the tongue is from the back of the mouth, which is called the backness of the tongue.
There are three primary height distinctions among vowels: front, back, and central.
In English, examples of front vowels are [i], [ɪ], [e], [ɛ], [æ]. These vowels are articulated relatively forward in the mouth. Examples of back vowels are [u], [ʊ], [o], [ɔ]. These vowels are articulated relatively far back in the mouth.. Examples of central vowels are [a], [ə]. These are vowels whose tongue positions are roughly between the front and back vowels.
These classifications, like the tongue heights, are quite relative, as different languages have different canonical tongue backnesses for different classifications.
Lip Rounding
Another aspect of vowel classification is the presence or absence of lip rounding. Some vowels, such as the vowels [o] and [u], are formed with a high degree of lip rounding. Such vowels are called rounded vowels. Some vowels, such as [i] and [ɛ], are formed without such rounding, and are called unrounded vowels.
In the next section, you will be introduced to the classification of vowels in terms of tenseness.
Tense vs. Lax
Another aspect of vowel classification is commonly characterized in terms of the tenseness or laxness of the articulators. Some vowels, such as the vowels [i] and [e], are formed with a high degree of tenseness. Such vowels are called tense vowels. Some vowels, such as and , are formed without a high degree of tenseness, and are called lax vowels.
Some languages have a similar distinction in the articulation of vowels. This classification is in terms of the position of the tongue root. In these languages, the primary classificational feature for the vowels [i] and [e] is not that the articulators are tense, but that the root of the tongue is pushed forward, opening up the pharynx. Such a condition is known as Advanced Tongue Root (ATR). Vowels such as [ɪ] and [ɛ], on the other hand, do not have ATR in those languages that have that distinction.
Summary
In this set of lessons, you have been introduced to the classification of vowel sounds in human language. The four classifications are as follows:
-
Tongue Height
-
Tongue Backness
-
Lip Rounding
-
Tense vs. Lax
Acoustics
What is Sound, Anyway?
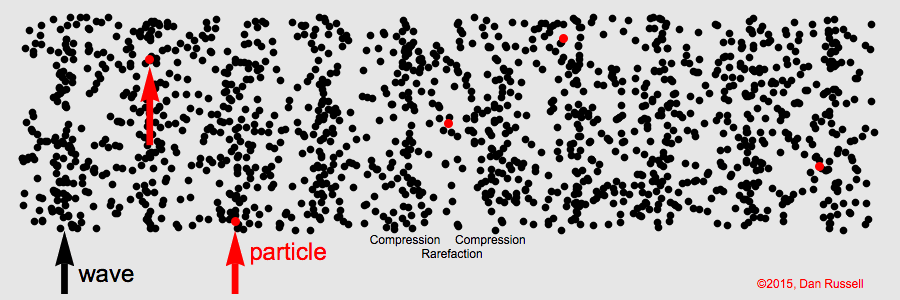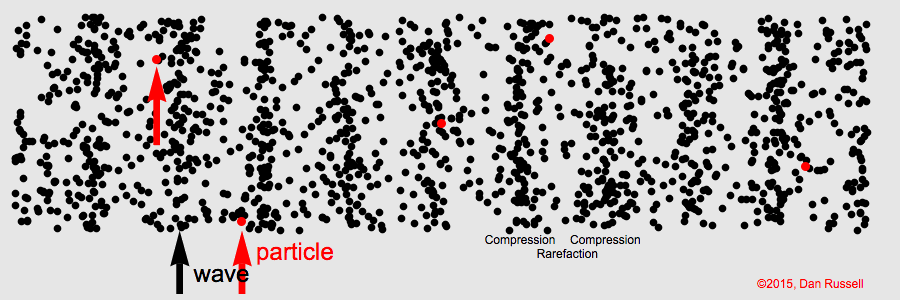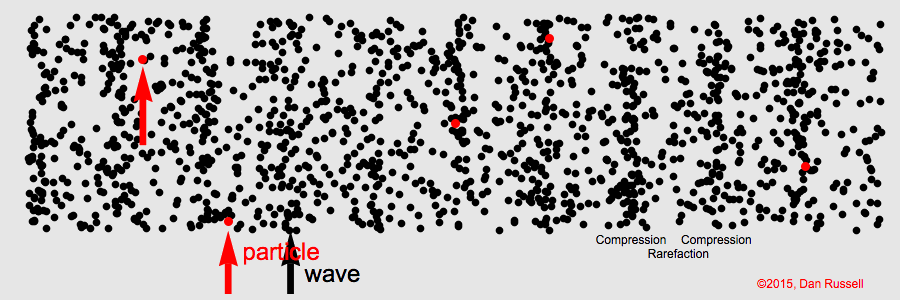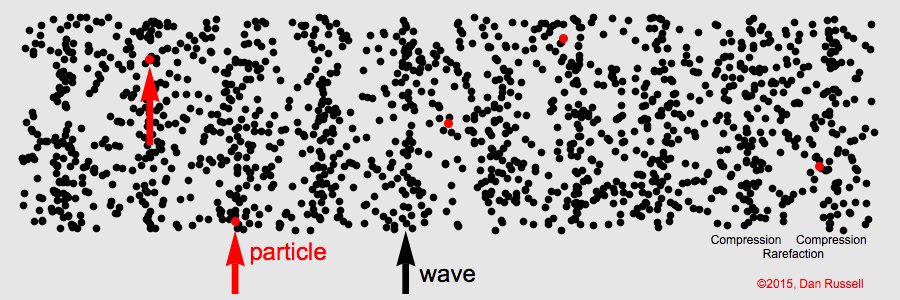
Sound is the result of the disturbance of air by some kind of movement. These disturbances of the air are called sound waves. Examples of the types of movement that cause this disturbance of air are the vibrations of a tuning fork, a guitar string, or a rubber band.
Let's take the guitar string as an example. The disturbance in the air is the movement of air molecules as a result of the movement of the string back and forth. When a guitar string is plucked, the string quickly moves back and forth. As it goes in one direction, the string pushes the air molecules closest to it. These air molecules then get closer to the air molecules surrounding it. This is called compression.
Here's a little note about air molecules. They prefer to be equidistant from each other. If an air molecule gets too close, the surrounding air molecules move away, attempting to reestablish the status quo.
So, when the air molecules closest to the string are compressed against the surrounding molecules, a chain reaction is set up, in which the surrounding air molecules move away from the first ones, and are then compressed against other air molecules, which then move away, and so on, and so on.
But that's not the end of it. As stated above, the guitar string moves back and forth. So, after the guitar string moves in the first direction, causing compression, it then moves in the opposite direction. As it does so, it pulls away from the surrounding air molecules. When this happens, those air molecules are now farther away from the air molecules on the other side of the string. This is called rarefaction. Since air molecules prefer to be equidistant from each other, they will move towards the molecules that are too far away. This, in turn, pulls them away from the surrounding air molecules, which then move to restablish the correct distance.
Then, the guitar string moves back again, causing compression, and the whole thing starts over again.
The following animation is an illustration of compression and rarefaction.
The arrow represents the movement of the guitar string, and the individual circles represent air molecules. The chain reaction through the surrounding air caused by compression and rarefaction is the sound wave.
As the guitar string vibrates at a certain number of times within a second, the surrounding air molecules within a certain distance from the string will move back and forth at that same number of times within a second.

Extracting Formant Values
Determining the formants of a vowel
A vowel's formants are the frequencies at which it resonates; that is, the frequencies which are particularly loud in an acoustic signal. Each vowel has its own set of signature formants. Vowels in different dialects also have different formant patterns. This tutorial is intended to show you how to determine vowel formants in your own speech.
Extracting formants is no simple task. It involves recording your sample and creating a spectrogram. Fortunately, there is software that allows a user to do all of these. The Language Samples Project uses Praat, a shareware product created by the linguist Paul Boersma. When using Praat, there is an intermediate step, which is to convert the recorded sample into a Praat object.
-
-
Recording your sample
-
To analyze your speech, Praat first needs to have a sound file to work with. Choose the "Record Sound..." option under the "New" menu. This calls up the SoundRecorder window.
-
Make sure the Sample rate is set at 44100. The Input Source may be either External Mic (recommended) or Sound In. You will know that the program can detect your speech because the Meter will react to any sound picked up by your microphone, even if it is not recording. If you do not see colours spiking in the Meter, double check to make sure your microphone is plugged in.
-
-
To obtain your sample, click the Record button and speak into the microphone. When you have finished, click Stop. You may listen to the recording again by clicking Play.
-
You may need to try more than once to get a good sample. Holding the microphone too close to your mouth will result in the signal having loud puffs and hisses. If this happens, try holding the microphone a few inches farther away.
-
-
If you are satisfied with your sample, you can now save it as a .WAV file. Do not click the Close button! Instead, open the "File" menu in the SoundRecorder window, and choose "Write left channel to WAV file." This will let you save your recording as a digital file. Give your sample a name and remember which folder you're saving it in. Once the file has been saved, you may close the SoundRecorder window.
-
Prevent future hassles by choosing an easily identifiable name. For example, if your name is Norma and the word you recorded is "thing", name the file "NormaThing.wav" instead of just "sample.wav", "Norma.wav", or "thing.wav". Otherwise, if Norma and Nicole both had files named simply "sample.wav" or "thing.wav", either one of them might be analyzing the wrong sample at a later date!
-
-
If you prefer, you may record your sample with any other recording software. Praat can import samples in a number of formats, including .WAV and .AIFF.
-
Making an object
-
Praat is designed to create different "objects" from sound files, and it can only work with these objects. Objects are normally listed in the Praat Objects window. The first object you need to add is the sound file itself. To do so, open the "Read" menu and choose "Read from file...". This will allow you to open your .WAV file as an object. Choose your sound file as you would choose any other document, by finding the proper folder and locating the file. When you click Open, Praat will add the file as a 'Sound' object.
-
You can rename and edit (clip, trim) this object without affecting the original .WAV file. So if you mess up, don't worry! You can higllight an unwanted Sound object and click Remove at the bottom of the window. Then read the .WAV file over again as a new object.
-
-
Your Sound object is now something that Praat can apply various functions to, creating more objects in the process. Some of these other objects include spectrograms. You can examine each object in a separate window, but the commands for doing so differ, diepending on the nature of the object.
-
Viewing a spectrogram
-
There are two ways of getting spectrograms in Praat. One way is to examine your Sound object itself, by clicking the Edit button in the Praat Objects window.
-
If you don't see an Edit button, make sure your Sound object is highlighted.
-
-
The Edit button opens another window, named for the Sound object. You should see a waveform in this window, as well as several drop-down menus.. To see the spectrogram, open the "Spectrogram" menu and choose "Show". The window should now be a split screen, with a waveform on top and a spectrogram on the bottom. The spectrogram is a graph that plots frequency ( y-axis) and amplitude (darkness) over time (x-axis).
-
Make sure you choose "Spectrogram > Show" and not "Spectrogram > View".
To have a better view of the spectrogram, delete the empty space that is probably found before and after your sample. Highlight those areas and choose "Edit > Cut".
-
-
You should now be able to see formants in the window, as dark, mainly horizontal bands. The horizontal cursor in this window can give you an idea of the frequencies of these formants. If you click anywhere on the spectrogram, you will see a time value at the bottom and a frequency value at the left. You should also see the intersection of a vertical and horizontal red line at the point on which you clicked. So if you click in the vertical centre of a formant, you can determine its frequency very easily.
-
Another way to view a spectrogram is to create a Spectrogram object. Instead of pursuing Step (3a), you would have your Sound object highlighted in the Praat Objects window. Click on the Spectrum - button and choose "to Spectrogram...".
-
You will see a window appear that gives you several options about the specifications of the spectrogram. Clicking the Defaults button will give you decent settings, but you may want to try reducing the Maximum Frequency to anywhere between 5000 and 7000 Hz. This will reduce the amount of empty space on the ensuing spectrogram, but it will also widen the formants, making it harder to determine their center with precision. Once you have settled on your settings, click OK.
-
Increasing the Analysis Width to 0.05 s will create a wide-band spectorgram.
-
-
You will see a new object in the Praat Objects window, called Spectrogram [name]. When this object is highlighted, click the View button to see the spectrogram. A window will appear with the Spectrogram plotted againts time and frequency, just like in Step (3b). However, this spectrogram will not give you precise frequency values; you would need to estimate a frequency using the scale on the y-axis. So while this way of obtaining a spectrogram gives you the option of viewing it to your specifications, it is harder to get a precise formant value.
-
Phonology

What is Phonology?
The study of phonology is the study of the patterned interaction of speech sounds. A fairly obvious observation about human language is that different languages have different sets of possible sounds that can be used to create words. For example, the sound is found in languages like Navajo, Coushatta, and Secwepemc, but not in English, Spanish, or French.
When one language borrows sounds from another language, the borrowing language must often adapt the words to fit the set of possible sounds in its inventory. For example, observe the following data, which illustrate borrowings into Hawaiian from English:
English Hawaiian
rice [ɹaɪs] [laiki]
wine [waɪn] [waina]
brush [bɹʌʃ] [palaki]
ticket [tɪket] [kikiki]
The data in the table above show that Hawaiian alters the English words in order to fit them into the possible inventory of sounds. For example, Hawaiian does not have the sounds [s], [ʃ], or [t]. Whenever the English word contains one of these sounds, it is replaced with the sound (eg. tɪket] > [kikiki] ). Also, Hawaiian does not have the sound . Whenever the English word contains this sound, it is replaced with the sound (eg. [ɹaɪs] > [laiki]). Similarly, the sounds [b] and [æ] are replaced with [p] and [a], respectively.
The following chart shows the sound inventory of Hawaiian:
However, besides the replacement of one sound for another, there are other differences between the English and Hawaiian words. In the Hawaiian forms, vowels are inserted that do not exist in the English forms. For example, you may note that in all the examples, a final vowel is added in the Hawaiian forms (eg. [waɪn] > [waina]). Also, a vowel is inserted whenever there are two consonants side-by-side in the English forms ([bɹʌʃ] > [palaki]). Finally, in the name Albert, there is a consonant added at the beginning of the word ([ælbɹt] > [ʔalapaki]).
This suggests that Hawaiian not only has restrictions on what sounds can occur in the language, but also conditions on how those sounds can be used in the formation of words. Based on the data above, we can propose three conditions on the interaction of sounds in Hawaiian:
-
Words in Hawaiian must not end in a consonant
-
Words in Hawaiian must not have two consonants in a row
-
Words in Hawaiian must begin with a consonant
A thorough study of Hawaiian words would show that these restrictions are not just restrictions on borrowed words, but also on all words in Hawaiian.
One of the goals of phonology is to describe the rules or conditions on sounds and sound structures that are possible in particular languages.
Tohono O'odham
Another major goal of phonology is to account for the similarities among human languages. That is, even though the different languages have different sets of sounds and different ways of arranging and patterning those sounds, there are a number of similarities across human languages. The following are a few of these similarities, often called universals:
-
All consonant inventories have voiceless stops
-
All languages have syllables
-
All inventories can be split into vowels and consonants
There are also some near-universals, such as the following:
-
Only two languages in the University of California Segment Inventory Database (UPSID), Rotokas and Mura, have no sonorant consonants
-
All languages in UPSID have some kind of , except Hawaiian
-
91.5% of the languages in UPSID have
One of the goals of phonology is to define the space of possible sounds and sound structures that all human languages draw from.

What are Phonemes?
What are Syllables?
What are Distinctive Features?
What are Rules?
What is Optimality Theory?
What are Phonemes?
Introduction
In this lesson, the goal is to learn about the motivations for distribution, allophonic variation, and the concept of the phoneme.
Major Terms
-
complementary distribution
-
phoneme
-
allophone
-
overlapping distribution
-
contrastiveness
The English Stops
Observe the following English words:
Is the boldfaced letter p, t, k pronounced the same in all of the words below? Hover on Frankenstein head to see the answer.



When you looked at the actual transcriptions, you should have seen that the transcriptions of the sounds represented by the letter p in the words were not the same. Take a look at the words with their transcriptions:
As you can see in the chart above, the letter p is transcribed in three ways:
You can demonstrate how these sounds are different on your own. Take your hand and place it in front of your mouth. Now say pat.
Did you feel the air against your hand? Now say spat.
When you say pat, you should feel more air against your hand than when you say spat. That extra puff of air is known as aspiration, and is represented in the transcription by the superscript "h".
Now, often, when one says tap, tip or top, there is no release of the "p" sound, and no air is present when the sound is articulated. This is known as an unreleased sound, represented by the "◌̚" next to the sound.




So now we know that the sound that English speakers hear as "p" can be pronounced in three different ways: regular, aspirated, and unreleased.
Look at the distribution of the different pronunciations across these data abovr. The distribution is not random. That is, we can predict where each pronunciation can occur. These facts can be shown as the following:
-
The "p" sound is pronounced as when it occurs at the beginning of the word.
-
The "p" sound is pronounced as when it occurs at the end of the word.
-
The "p" sound is pronounced as everywhere else.
How would you transcribe the "p" sound in each of the following words?
park
grip
speak
The facts thus far about the data that we've been looking at are the following:
-
The "p" sound in the data is pronounced in three different ways.
-
This difference in pronunciation is not random, but predictable, depending upon where the "p" sound occurs in the word:
-
-
Beginning of the word
-
End of the word
-
Anywhere except at the beginning or the end
-
It is important to note that the places in which the different pronunciations occur are unique, and do not overlap. That is, you never find [pʰ] at the end of the word, or [p̚] at the beginning of the word, or [p] in either place.
Since these different pronunciations never appear at the same place in words, they are said to be in complementary distribution.
The Phoneme
This brings us to the concept of the phoneme. A phoneme is a mental representation of a sound that has predictable variants. Each of the variants of that sound is called an allophone.
For example, in the case of the English stops, the sounds [pʰ], [p̚], and [p] are all predictable variants of one sound. They are in complementary distribution, as discussed above. Therefore, they must all be allophones of a phoneme.
How do we represent this phoneme? For reasons which will become clearer in later lessons, the phoneme is represented by the sound which has the broadest distribution, or occurs in the most places. Since [pʰ] and [p̚] can only appear at the beginning or end, and [[pʰ], [p̚]] appears everywhere else, [[pʰ], [p̚]] has the widest distribution.
Therefore, the phoneme is . The /p/ indicates that the representation is a phoneme, not a single sound.
Truth, Justice and the Linguistic Way
Still confused? Ok, imagine Clark Kent and Superman. We know that Clark Kent and Superman are the same person, right? Each persona is a variant of a single person, even though they look and act differently.
Even if we didn't know they were the same person, we could figure it out (because we're smarter than Lois and Jimmy) by looking at the different contexts in which we see Clark Kent and Superman. Here are the contexts we find Clark Kent:
-
On the trail of a story
-
In the supermarket
-
Buying a new suit for a date with Lois
-
etc.
Clark Kent shows up during contexts of being a reporter, being the owner of a refrigerator, being a suitor for Lois, etc. Now what about Superman:
-
The world is going to explode in 5 seconds
-
Jimmy is being held captive by Braniac
-
etc.
So Superman appears only in the context of being a hero.
In other words, Clark Kent and Superman never appear at the same in the same place in the same context. This means that they are in complementary distribution.
Since they are in complementary distribution, if they were sounds, they would be allophones of the same phoneme.
Which is the phoneme, Clark Kent or Superman? Well, since Superman only appears in the context of being a hero, Clark Kent has the wider distribution. Therefore, the phoneme is /Clark Kent/.
Overlapping Distribution
Earlier, we discussed the term complementary distribution. Again, sounds are in complementary distribution if they never appear in the same contexts.
Sometimes, sounds do appear in at least some of the same contexts. When this happens, the sounds are in overlapping distribution.
For example, observe the following data:
pat [pʰæt]
bat [bæt]
car [kʰæt]
Note in particular the sounds [pʰ], [b], and [kʰ]. In each form, one of those sounds appears at the beginning of the word. Therefore, each one of the sounds can appear in the context of the beginning of the word.
Based on that fact, the sounds [pʰ], [b], and [kʰ] cannot be in complementary distribution, because they can appear in the same context.
This leads to the conclusion that [pʰ], [b], and [kʰ] are in overlapping distribution, since in the context of the beginning of the word, each of those sounds can appear.
Furthermore, if these sounds are in overlapping distribution, they must be variants of separate phonemes. That's an important relationship. Say the following to yourself as a mantra:
complementary distribution = allophones of the same phoneme
overlapping distribution = allophones of separate phonemes
Repeat this to yourself as needed.
Holy Aspiration, Batman!
Let's go back to the superhero analogy for a moment. We'll now add Bruce Wayne and Batman into our data set. As with Superman, Batman appears in the context of being a hero, while Bruce Wayne appears everywhere else (i. e. they are in complementary distribution).
Hence [Bruce Wayne] and [Batman] are allophones.
Now, consider just Superman and Batman. Are they allophones of a single phoneme?
Contrastiveness
So, to answer the last question, Batman and Superman must belong to different phonemes, because they can both appear in the context of being a hero, and are therefore in overlapping distribution.
Another useful term to know is contrastiveness. When sounds are in overlapping distribution, they are contrastive. This is to indicate that the sounds can create lexical contrasts.
What does that mean?
Basically, it means that you can change the meaning of a word simply by changing one of the sounds to another. For example, if you have the word pat [pʰæt], you can change the meaning of the word to something else by changing the [pʰ] to a [b], giving you the word bat [bæt]. Therefore, the sounds [pʰ] and [b], are contrastive.
Take the word pat again. If you change the [pʰ] to [p], is the result a different word? Not in English, it isn't. It sounds a little strange, but it's still recognizable. Therefore, these sounds are not contrastive.
Summary of Phonology Lesson 1: What are Phonemes?
In this lesson, we looked at concepts of sound distribution. If sounds are in complementary distribution, they cannot appear in the same contexts. If sounds are in overlapping distribution.
Furthermore, if sounds are in complementary distribution, they are allophones of the same phoneme. If sounds are in overlapping distribution, they are allophones of different phonemes.
If sounds are allophones of different phonemes, they are contrastive.
What are Distinctive Features?
Introduction
In this lesson, the goal is to learn about the motivations for distinctive features in phonological theory.
Major Terms
-
natural class
-
distinctive features
-
[± consonantal]
-
[± sonorant]
-
[± approximant]
-
[± voice]
-
[± spread glottis]
-
[± constricted glottis]
-
[± continuant]
-
[± nasal]
-
[± lateral]
-
[LABIAL]
-
[± round]
-
-
[CORONAL]
-
[± distributed]
-
[± anterior]
-
[± strident]
-
-
[DORSAL]
-
[± high]
-
[± low]
-
[± back]
-
[± tense]
-
-
[RADICAL]
-
In the first section, you will be introduced to the idea of a natural class.
Natural Classes
Recall the previous lesson, which discussed the distribution of aspiration in English. In that lesson, it was shown that certain consonants are aspirated at the beginnings of words. However, observe the following data, remembering that a * refers to an ungrammatical form.
pat [pʰæt] sat [sæt] *[sʰæt]
tap [tʰæp] lap [læp] * [lʰæp]
cap [kʰæp] gap [gæp] * [gʰæp]
The data above illustrate that the consonants that are aspirated at the beginnings of words forms a subset of the English consonants.
The sounds [p], [t], [k] aspirate at the beginnings of words, but consonants such as [s], [l], [g] do not aspirate at the beginning of words.
Since there are rules of language that apply to only certain sets of words, it is useful to refer to such sets as being composed of a certain feature or features that are not shared by other consonants in the larger set. These subsets are known as natural classes.
Further, the features that define natural classes are known as distinctive features. The next sections will further elaborate the idea of distinctive features and introduce many of the specific features that have been proposed for human language.
Distinctive Features
So, we have the concept of distinctive features. These distinctive features allow us to define natural classes of sounds. But how do we define these features?
Well, first of all, the features we define should be adequate to define some natural class of sounds. But remember that a natural class is composed of sounds that share a certain feature or group of features. Clearly, different sounds should not share all of the same features. So, if the proposed set of distinctive features in human language is adequate, every sound should have a unique set of features.
In the phonetics lessons, it was discussed that different sounds are classified by the features associated with their specific articulations. For example, consonants are classified in terms of their place of articulation, manner of articulation, and voicing. Each sound was represented by a unique combination of these features.
So, a good place to approach distinctive features might be those used in the phonetic classifications discussed in the phonetics lessons. Are these features adequate? If they are, they should be able to define all natural classes of sounds, and every sound should be definable in terms of those features.
To test all the natural classes of human language is a long drawn out process, and such features are still being tested. However, we don't have to go too far afield to discover that places of articulation, manners of articulation, and voicing are not adequate. Observe the following data from Scottish English:
writhe [ræð] mile [mʌil]
nine [nʌin] beige [beːʒ]
tease [tiːz] road [rod]
love [lʌːv] horn [horn]
peace [piːs] food [fud]
boar [boːr] life [lʌif]
Question: Based on the above data, before which consonants do the vowels [i, e, a, o, u, ʌ, ʌi ] appear, and before which consonants do the vowels [iː, eː, aː, oː, uː, ʌː, æ] appear?
Distinctive Features
The previous section presented you with some data from Scots English. In that data, it was shown that the vowels and the vowels appeared before the following sets of consonants
[i, e, a, o, u, ʌ, ʌi ] [iː, eː, aː, oː, uː, ʌː, æ]
_n _θ _ð _z
_s _l _v _ʒ
_d _m _r
Question: In looking at these two sets of environments (environments are those sounds that follow or come before a particular sound), are the vowels [i, e, a, o, u, ʌ, ʌi ] and the vowels [iː, eː, aː, oː, uː, ʌː, æ] in complementary or overlapping distribution? If you're not sure, review the section on phonemes (hint: remember Superman and Clark Kent?).
Distinctive Features
Based on the data shown in the previous section, it is clear that the vowels [i, e, a, o, u, ʌ, ʌi ] and the vowels iː, eː, aː, oː, uː, ʌː, æ] are in complementary distribution.
Let's run through the argumentation.
The vowels [i, e, a, o, u, ʌ, ʌi ] can appear before the following set of consonants: [f, m, θ, s, n, d, l] .
The vowels [iː, eː, aː, oː, uː, ʌː, æ] can appear before the following set of consonants: [v, ð, z, ʒ, r].
The two sets of consonants are not the same.
Therefore, the vowels [i, e, a, o, u, ʌ, ʌi ] do not appear in the same contexts as the vowels [iː, eː, aː, oː, uː, ʌː, æ].
Therefore, the two sets of vowels are in complementary distribution.
Now that we know that the two sets of vowels are in complementary distribution, we can theorize that they are allophones of the same phoneme.
Question: if they are allophones of the same phoneme, which set represents the phoneme? (Which one is Clark Kent?)
Distinctive Features
Remember from the section on phonemes that the phoneme is represented by the allophone that has the broadest environment. In this case, the vowels from the set [i, e, a, o, u, ʌ, ʌi] would represent the phonemes /i/, /e/, /a/, /o/, /u/, /ʌ/, /ʌi/.
The other set of vowels represent allophones of those phonemes. When we discussed English stops, we defined the contexts in which the aspirated stops appear and when the unreleased stops appear. We want to do the same here for the vowels [iː, eː, aː, oː, uː, ʌː, æ].
This is where natural classes come in handy. In order to define where the vowels [iː, eː, aː, oː, uː, ʌː, æ] appear, we simply have to define the features of the natural class of consonants that can follow those vowels. These features should define this class uniquely; that is, the features that define that natural class should not also define the class of consonants that follow the short vowels, as that would defeat the purpose.
So, to begin with let's look at the set of consonants in question in terms of the phonetic classifications that we determined before.
Here's the set of consonants: [v, ð, z, ʒ, r].
Let's start with Place of Articulation. Do all these consonants share the same Place of Articulation?
Move on to the next section to see the answer.
Distinctive Features
So, the question is: do all of the consonants in the set [v, ð, z, ʒ, r] share the same place of articulation?
The answer is no. The consonant [v] is a labiodental consonant, the consonant [ð] is an interdental consonant, the consonants [z] and [r] are alveolar consonants, and the consonant [ʒ] is an alveopalatal consonant.
Therefore, we cannot define the natural class in terms of Place of Articulation. Now, let's see if we can define this set in terms of Manner of Articulation. Do the consonants in the set [v, ð, z, ʒ, r] share the same manner of articulation?
Try to determine this for yourself and then go to the next section for the answer.
Distinctive Features
So, the question is: do all of the consonants in the set [v, ð, z, ʒ, r] share the same manner of articulation?
The answer is almost, but no. The consonants [v], [ð], [z], and [ʒ] are all fricatives. However, the consonant [r] is a trill, not a fricative.
Therefore, we cannot define the natural class in terms of Manner of Articulation. Now, let's see if we can define this set in terms of voicing. Do the consonants in the set [v, ð, z, ʒ, r] share the same voicing?
Try to determine this for yourself and then go to the next section for the answer.
Distinctive Features
So, the question is: do all of the consonants in the set [v, ð, z, ʒ, r] share the same voicing?
The answer is yes. All of the consonants are voiced.
Therefore, we can define the natural class at least partially in terms of Voicing. However, the classification of voicing doesn't uniquely define this set of consonants as opposed to the consonants that define the other environment. That is, if we were to define the consonants [v, ð, z, ʒ, r] as voiced consonants, we would have to say that the vowels [iː, eː, aː, oː, uː, ʌː, æ] appear only before voiced consonants. However, the vowels [i, e, a, o, u, ʌ, ʌi ] appear before the consonants [f, m, θ, s, n, d, l] and four of those consonants are voiced.
Therefore we need some other feature besides place of articulation, manner of articulation and voicing to define the set [v, ð, z, ʒ, r] as a natural class of consonants. This is where distinctive feature theory comes in.
Distinctive Features
One can think of distinctive features as a set of binary "switches" that all sounds have as part of their mental representation. Every sound has a unique configuration of these "switches". For each sound, some of the switches may be turned on, while others are turned off. Which switches are turned on and which are turned off determine what kind of sound is produced.
To represent these switches, every switch is given a name, such as [voice], [distributed], etc. (See the last section of this lesson for a more complete list of the features).
To represent whether the switch is turned on or off, either a + or - is placed before the name. For example, if the switch [voice] is on, it is represented as [+voice]. If it is off, it is represented as [-voice].
We noted that the consonants in the set [v, ð, z, ʒ, r] are all voiced. Therefore, each of the sounds has the feature [+voice], which indicates that the switch [voice] is turned on.
The only real exceptional features are the place features [LABIAL], [CORONAL], [DORSAL], and [RADICAL]. For a number of linguists, these features do not have an on-off switch like other features. Instead, some sounds have the feature, and some don't. The reasons for this, and the implications of this will not be discussed here. You need only remember that these particular features act a little differently.
Distinctive Features
In the case of Scots English, what we need is to define a feature that is shared by all of the consonants in the set [v, ð, z, ʒ, r] that is separate from voicing. One such feature that has been proposed is the feature [continuant]. Sounds that are [+continuant], that is, that they are characterized has having this feature, are produced with continual airflow through the oral cavity. Sounds such as fricatives and some approximants have this feature, but stops and nasals do not. Thus this feature divides speech sounds into two sets that are not part of the classification system learned in the phonetics section.
Now if we look at the set [v, ð, z, ʒ, r] again, we see that they are all fricatives or approximants. So now we have two ways of defining this set as a natural class. These consonants are all both [+voice] and [+continuant]. Can any of the consonants in the set [f, m, θ, s, n, d, l] be defined by both of these features?
Well, the consonants [f, s, θ] are [+continuant], being fricatives, but they are not [+voice]. The consonants [m, n, d] are [+voice], but not [+continuant].
What about [l]? The consonant [l] is often discussed as being ambiguous. In some languages, [l] is [+continuant], and in some languages it is [-continuant]. It would appear that in Scots English, the consonant [l] is [-continuant].
Therefore, the features [+continuant] and [+voice] do, indeed, define the set [v, ð, z, ʒ, r] as a unique natural class.
In the lesson What are Rules?, you will learn about how to use phonemes and distinctive features to create phonological rules. In the next lesson, What are Syllables?, you will learn about the concept of the syllable, and the evidence to support this phonological entity.
The next section in this lesson gives a list of distinctive features that have been proposed for human language.
Distinctive Features
The following is a list of proposed distinctive features, compiled in Gussenhoven and Jacobs (1998):
[± consonantal]
Sounds which are [+ consonantal] are those which have some kind of constriction along the center of the vocal tract. This constriction must be at least as narrow as that required for a fricative.
[± sonorant]
Sounds which are [+sonorant] are those which are produced with a constriction in the vocal tract that allows the air pressure both behind and in front of the constriction to be relatively equal. This feature generally divides the sound system into sonorants ([+sonorant] sounds), which are nasals, approximants, glides, and vowels, and obstruents ([-sonorant] sounds), which are oral stops, fricatives, and affricates.
[± approximant]
Sounds which are [+approximant] are those sounds whose constriction allows for a frictionless escape of air.
[± voice]
Sounds which are [+voice] are those which are produced with vibration of the vocal folds.
[± spread glottis]
Sounds which are [+spread glottis] are those produced with a glottal configuration that produces audible glottal friction. For example, the aspirated stops in English are [+spread glottis]
[± constricted glottis]
Sounds which are [+constricted glottis] are those which are produced with the vocal folds drawn together and tense.
[±continuant]
Sounds which are [+continuant] are those which are produced without a central blockage in the vocal tract. For example, fricatives have a central constriction, but there is no complete blockage of the air, and they are therefore, [+continuant].
[±nasal]
Sounds which are [+nasal] are produced with nasal airflow.
[±lateral]
Sounds which are [+lateral] are produced with airflow passing through one or both sides of the tongue, which is in contact with the
central part of the oral cavity.
Place Features
These features, [LABIAL], [CORONAL], [DORSAL], and [RADICAL] are features that are often characterized as not being + or -, but rather, either a consonant has the feature or not.
What are Syllables?
Introduction
In this lesson, the goal is to learn what syllables are, and the evidence that motivates them.
Major Terms
-
syllable
-
nucleus
-
onset
-
coda
-
syllabification
-
Maximum Onset Principle
-
syllabic resonants
The Beat Goes On
To begin with, you should be made aware of the fact that you, as a speaker of language, have some intuitions about what a syllable is. In fact, you may already have learned about syllables in your previous education.
In rather basic terms, a syllable is a timing unit for language. Words in language take certain amounts of time to utter. This time can be measured in terms of syllables.
cat
pencil
unbelievable
Each of the preceding words had differing lengths, each measureable in terms of syllables. The first word is composed of one syllable, the second word is composed of two syllables, and the final word is composed of five syllables.
In the next sections, there will be a discussion of the structure of the syllable, and the motivations for considering the syllable as a phonological entity.
How do we know that syllables exist?
One reason is that we can count them. On the previous page, we talked about syllables as timing units. Language users can perceive those units and even count them. If I give you the word antidisestablishmentarianism, you know that there is more than one syllable involved. You even know that it's probably more than two or three. So, you have some perception of some words being perceptually longer than others in terms of syllables.
Here's another reason.
In English, we use an alphabetic system to write sounds. More or less. An strict definition of an alphabetic system is one in which one symbol refers to one sound. For example, the word mat has the following phonological representation: [mæt]. In this word, the symbol m can be said to refer to [m], the symbol a can be said to refer to [æ], and the symbol t can be said to refer to [t].
Of course, when we get to words like rough, show, and the like, this breaks down a bit. But you get the idea.
Other languages use a system in which one symbol refers not to a single sound, but a group of sounds. Observe the following from Cherokee, and Iroquoian language spoken in Oklahoma and North Carolina:
ᎦᏁᎵ ganeli 'married person'
ᎦᏚ gadu 'bread'
ᏁᏩᏓ newada 'hominy'
ᏑᎵ suli 'buzzard'
The word gadu has one of the same symbols as ganeli, the symbol Ꭶ. Both ganeli and gadu have the 'ga' combination. The words newada and suli also have one of the same symbols as ganeli, the symbols Ꮑ and Ꮅ . Further, they each have one of the same sound combinations as ganeli, 'ne' and 'li'.
Therefore, one can see that there is a match between a Cherokee symbol and a combination of consonants and vowels.
If we separate consonant and vowel sequences into syllables, then we can say that Cherokee uses a writing system in which one symbol represents a syllable.
In the next section, another piece of evidence regarding the existence of the syllable is discussed.
Other Evidence
Observe the following data from English:
-
Atlantic [ætlæntik]
-
Atlanta [ætlæntə]
-
hitlist [hɪtɪst]
-
potlatch [patlæʧ]
In each of these examples, there is a sequence in the middle of a word.
However, in English, there is no way to begin a word with the sequence . So, words like *tlap, *tling, etc. are not possible words of English.
Using the idea of syllables, can you explain why?
The next section will discuss a possible solution.
Why Can't English Words Begin with "tl"?
Well, we could just say that this is a special rule of English, but that would only restate the problem. We still would want to find out what the underlying reason is.
But, if we have the concept of syllables, then there is a possible solution.
As we noted earlier, [tl] is perfectly acceptable in words like atlantic and hitlist. It is also possible to state that, in each such case, the [t] and [l] are conceivable part of two separate syllables:
-
Atlantic [æt] [læn] [tik]
-
hitlist [hɪ] [tɪst]
In a hypothetical word such as [tlap], there is only one syllable, and both [t] and [l] are part of that one syllable.
So, perhaps the rule is that a [tl] combination can't be in the same syllable.
Such an explanation is only possible if syllables exist as phonological entities.
On the next page, there is discussion about the parts of syllables.
What's in a Syllable?
What sorts of things are in a syllable? Let's take a simple example to start with: cat.
Let's take that one step further and use IPA to represent the word cat: [kæt].
It's not very hard to determine that [kæt] has one syllable. In some varieties of English, the word cat is pronounced with two syllables, but that would have a different IPA representation. The pronunciation [kæt], however, has one syllable.
So, what's in it? Well, there's a [k], a [æ], and a [t]. If we simplify that a little, there is are two consonants with a vowel in the middle, or we have a CVC sequence, where C is a consonant, and V is a vowel.
Based on this, we know that a syllable can be composed of a consonant followed by a vowel, followed by a consonant.
What other structures can a single syllable have ? Think of different single syllable words.
What's in a Syllable?
Observe the following monosyllabic words and decide what kind of structure each word has:
-
tea [ti]
-
a [ʌ]
-
at [æt]
-
tree [tri]
-
ask [æsk]
-
skirt [skɪt]
-
task [tæsk]
-
stamp [stæmp]
-
strap [stræp]
-
stray [strɛ]
-
strength [strɛŋθ]
-
strengths [strɛŋθs]
Since each of these is monosyllable, they should represent a possible syllable.
Thinking in terms of just consonants and vowels for the moment, what are the possible syllable structures represented above (for example, the word tea [ti] represented the structure CV, since it is composed of a consonant [t] and a vowel [i].
What's in a Syllable?
In terms of consonants and vowels, the following words represent the following structures:
-
tea [ti] CV
-
a [ʌ] V
-
at [æt] VC
-
tree [tri] CCV
-
ask [æsk] VCC
-
skirt [skɪt] CCVC
-
task [tæsk] CVCC
-
stamp [stæmp] CCVCC
-
strap [stræp] CCCVC
-
stray [strɛ] CCCV
-
strength [strɛŋθ] CCCVCC
-
strengths [strɛŋθs] CCCVCCC
One fact that one may notice from these structures is that they all contain a vowel. This vowel is known as the nucleus of the syllable.
Another fact is that a syllable may have a consonant or string of consonants before the vowel. These consonants that are before the vowel are called onsets.
Finally, a syllable may have a consonant or string of consonants after the vowel. These consonants that are after the vowel are called codas.
The following diagram is an illustration of a syllable such as the one in cat:
In the next section, there will be a discussion on syllabification.

Syllabification
In this section, there will be a discussion on how to separate polysyllabic words into syllables. This is called syllabification.
Let's take a word like banana [bənænə]:
Now, we can look at the word banana in terms of consonants and vowels: CVCVCV.
The first step is to find the nuclei of the syllables in the word. There are three vowels, and since vowels are usually nuclei, there are three nuclei, and thus, three syllables.
Therefore, at this point, we have the following structure:
Now, we have to decide which consonants are onsets, and which consonants are codas.
In working with English, it is usually best to give every syllable an onset, where possible. So, if we give every syllable an onset, we have the following structure:
In the above structure, every segment is syllabified, and thus, we are done.
Let's take another word: racket [rækət].
In terms of consonants and vowels, the word racket has the following structure: CVCVC. As stated above, the first step is to find the nuclei of the syllables in the word. In this case, there are two vowels.
Now, we can give both syllables an onset:
Now, we have a consonant that is not associated to some syllable structure. Therefore, we can associate it to the end of the final syllable:
Since this consonant is at the end of the syllable, it is considered a coda.
Now try the word flood on your own. As practice in transcribing words into IPA, which of the following transcriptions of flood would be correct? To see if you're correct, place your mouse pointer over the transcription that you think most closely matches the pronunciation of the word flood.
[flood] [flud] [flʌd]
If you had trouble with the transcription, you might want to review the section on the International Phonetic Alphabet.
Once you've determined what you think the syllabification of flood is, go the the next section.





Syllabification
Well, we know that the consonant-vowel structure of flood is CCVC. Move your mouse pointer over the structure to see if you chose the right syllable structure.
C C V C
In this structure, you can see that there is only one syllable, and two onsets. This results because it is the only way to incorporate all consonants and vowels into the syllable structure. Such groups of onsets (or codas, in some cases) are called tautosyllabic consonant clusters.
Now, what about a word like cutlass [kʌtləs]?
First, we syllabify the vowels:
Then we provide onsets where possible:
Now, the final consonant clearly has to be syllabified as the coda of the final syllable (just like in racket), since it has no other option:
But, what about the other consonant? There would appear to be two possible syllabifications:
Which of the two possibilities would you choose? Why?
Go on the next section to see a discussion of which of the two is argued for here.





Which one did you choose? There is a strong argument for the following structure, an argument that we discussed earlier.
Remember the discussion of words like atlantic and atlas? The hypothesis put forth in that section is that the [tl] combination was possible in the middle of these words because they had to be from different syllables. Otherwise, they would also be possible at the beginnings of words. This hypothesis basically states that [tl] is not a possible onset cluster. Therefore, a syllabification in which [tl] is parsed as a consonant cluster should be disallowed.
What about a word like caprice [kʌpris]? Which of the following structures would you choose?
Maximum Onset Principle
In the case of the word caprice, by the rules that we have defined so far, it would seem that both of the following structures are possible.
How could both structures be possible in caprice, but not in cutlass?
Remember how structure (b) was disallowed for cutlass. Structure (b) was disallowed, because it would include a [tl] as a tautosyllabic consonant cluster. We knew that [tl] was not a good onset cluster in English because of the fact that it could not appear at the beginning of English words.
In the case of caprice, structure (b) would have a [pr] as a tautosyllabic consonant cluster. Words such as price, pride, probably, etc. show us that [pr] is a perfectly acceptable onset cluster, because each of those words begin with [pr].
Therefore, we could not rule out structure (b) for caprice, as we did for cutlass.
So, which is it then? One possible answer is that structure (b) is the correct structure, because it fills up the onset of the second syllable with as much content as is possible, given the restrictions on onset clusters. This is known as the Maximum Onset Principle, which states that as many consonants as possible will be syllabified into the onset. This principle is an extension of the idea that onsets are syllabified before codas. This is generally accepted as a universal concept: syllables prefer onsets, and disprefer codas.
In the next section, syllabic resonants will be discussed.
Syllabic Resonants
Earlier in this lesson, it was stated that nuclei of syllables were generally vowels. This is not always the case. In English, it is possible for some types of consonants to serve as nuclei of syllables.
Say the word babble.
How many syllables does it have?
Hopefully, you said two.
The transcription of the word babble used in this website would be [bæbl̩], where [l̩] is a consonant.
Let's try to syllabify this. The consonant-vowel sequence would be CVCC. However, we know that there are two syllables, but only one vowel. So, something has to serve as the nucleus of the second syllable.
Certain consonants, like [l], [r], [m], and [n] can serve as nuclei for syllables. When they are used as syllabic nuclei, they are called syllabic resonants, and are written as [l̩], [r̩], [m̩], [n̩].
Therefore, the syllabification of the word babble would be:
The next section summarizes all that has been discussed in this lesson.

Summary
In this lesson, there was discussion of the timing units of language that are known as syllables.
To begin with, there was discussion of the evidence supporting their existence as phonological entities. The following are the types of evidence discussed:
-
Syllables are countable
-
There are writing systems that are arguably based on the concept of the syllable
-
The concept of the syllable allows for an elegant explanation for limitations on consonant clusters in English
There was also discussion of the different parts of the syllable: onset, nucleus, coda. These parts are schematized below:
Finally, this lesson provided instruction on the syllabification of words in English. The basic process is as follows:
-
find a nucleus for each syllable in the word
-
give every syllable an onset, and fill up the onset position with as many consonants as are allowed in the syllable structure
-
associate any remaining consonants to the coda position of the syllable.
Interactive IPA charts
use alt+right/left arrow to go backward/forward to pages you have already visited
mrI ipa chart
(visual)
use alt+right/left arrow to go backward/forward to pages you have already visited
place of articulation
American English IPA chart
(+descriptive model)
The chart below is American English IPA. For more details, please go to the interactive American English IPA (under the chart) which helps you to visualize and perceive place and manner of sounds.

IPA practice sheet
(you can print these pages (right click + save -> print) and practice consonants' place and manner of articulation


